0009: Postback Processor Phase 2 Architecture
STATUS
Accepted
CONTEXT
Currently, when MMPs have a conversion that triggers a postback, they are making the postback directly to Tune. This has many shortcomings, causing data loss. Specific shortcomings of Tune are that it has no capability to process fraudulent postbacks and it will ignore any postback that comes in for paused campaigns.
To address these shortcomings, we would like to directly capture these postbacks ourselves to have a more complete picture of the MMP activities. This cleaner and more comprehensive feed of data will be used for: more sophisticated fraud detection, elimination of breakage, and improved cost reporting and invoicing.
Beyond collecting this data, Tune will still need to receive postbacks for upstream processing by our systems and publishers. As a result, the new system must make postback calls to Tune.
Considered Options
-
- An asynchronous queue based system for receiving and forwarding postbacks. The exposed API would be API Gateway, and the backing queue system would be:
- a. Kinesis -> high throughput, no guaranteed delivery.
- b. SQS -> very high throughput, guaranteed at least once delivery. - DECISION
- c. SQS Fifo -> lower throughput, guaranteed exactly once delivery.
-
- Synchronous API Gateway Lambda to store and forward postbacks.
DECISION
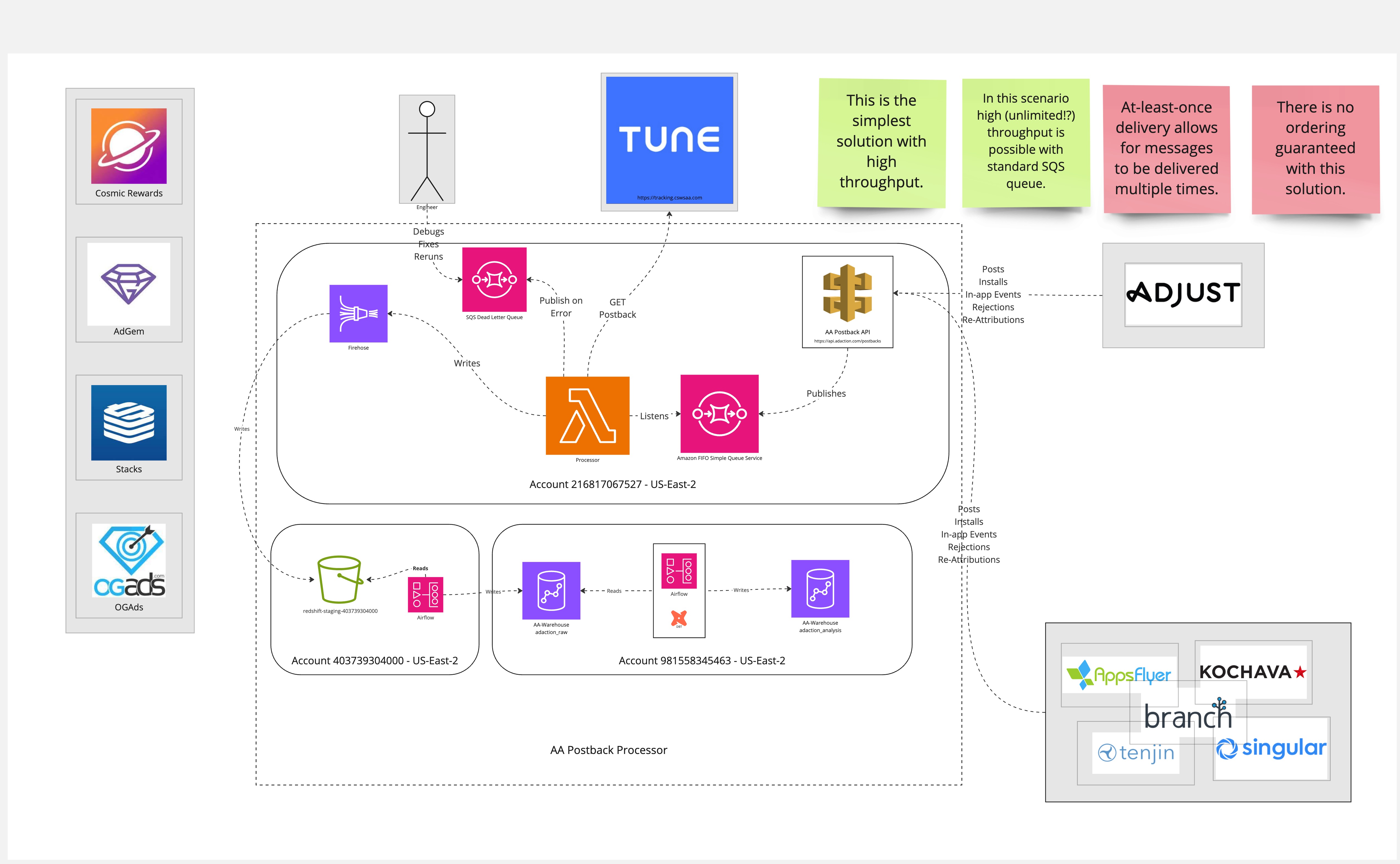
The postback processor will be comprised of API Gateway backed by an SQS queue to receive MMP postbacks. The queued postback events will be handled by lambdas whose responsibility will be to both send postbacks to Tune, and send the data to Data Firehose for storage in Redshift.
Sequence
Architecture
The full C4 System Context and Container Context diagrams for phase 1, 2, and 3 are available in this miro doc. Please see the frame titled "Phase 2 Container Context Option C (High throughput, at-least once delivery, order not guranteed)" for this particular solution. Provided as an image here for convenience:
DATA Load
This system uses Redshift's COPY command to load the firehose data into
Redshift in an Airflow DAG. This setup is very similar to the one detailed
in Analytical Events Architecture.
RAW schema
The preliminary schema is very basic relying on a semi-structured field to capture all of the request parameters. Request parameters are not standardized across the different MMPs, so we haven't attempted to extract and normalize the parameters yet.
Other options
A synchronous implementation was ruled out due to high risk of data loss. With a queue (and connected dead-letter queue) if any system or code issue arises we can replay messages.
Kinesis was ruled out due to its lack of delivery guarantee. Rather it provides at most once assurances. Additionally it does not provide a dead letter queue.
Simple Queue Service does provide a dead letter queue, and guaranteed delivery. SQS FIFO was appealing for its exactly once delivery and guaranteed ordering. However, it is more expensive and has a much lower throughput compared to basic SQS (300 messages/sec vs unlimited). Additionally, Tune can handle duplicate postbacks, making exactly once delivery more of a luxury than a must have.
Alternate queue systems were dismissed in preference for AWS managed infrastructure.
We briefly explored a High Availability solution for API gateway and SQS. This would use region redundancy and DNS failover for API Gateway, and distributed queues for SQS. Having no HA is deemed an acceptable risk for the following reasons:
* Most (if not all) MMPs will attempt several retries over a
period of time if their postbacks fail.
* The data can still be accessed via MMP reports or APIs.
* The SLA of the services is quite high (99.9% for SQS and 99.95%
for API Gateway).
* The potential revenue loss for downtimes connected to those SLA
does not justify the added expense for a HA solution.
CONSEQUENCES
- Positive outcomes
- Robust fault tolerant solution
- Comprehensive dataset for analysis
- Negative outcomes
- No high availability: If SQS or API Gateway have outages the system will be unavailable.
- Duplicates are possible in firehose due to more than once SQS delivery. While not ideal, this can be mitigated during dbt analysis model generation.
Risks
- An extended AWS outage (in either SQS or API Gateway) could lead to lost postbacks and thus lost data and revenue.
NOTES
References
- SQS SLA
- API Gateway SLA
- Postback Architecture Miro Board
- PR #37: docs(postback-processor): Postack Proc Phase 2 Architecture
- PR #68: fix: Flatten indexes of docs to prep for auto-index merge
- PR #127: docs: backfill PR reference links for existing ADRs
Original Author
Ron White
Approval date
18-Sep-24